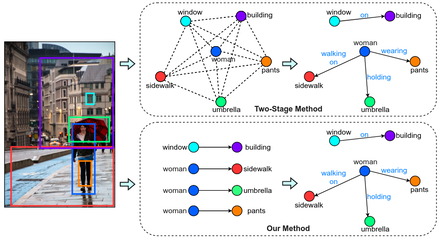
Scene understanding is a challenging topic in computer vision, robots and artificial intelligence. Given one or more images, we want to infer what type of scene is shown in the image, what objects are visible, and physical or contextual relations between the observed objects. This information is important in many applications, such as robot navigation, image search, or surveillance applications.
Relations between objects can be given by physical information, such as "in front of " or "above". More abstractly, however, humans usually consider implicit relations between objects: For instance, both a table and the chairs around the table are "above" the floor. A human observer, on the other hand, would rather consider them to be a single group of objects. In other words, table and chairs define a relation which is more than just "in front of "or "next to". This type of implicitly defined additional information is what we consider as semantic or contextual information.
We estimate semantic information defined between objects in the scene, and construct a so-called scene graph. Scene graphs neatly represent all the objects within a scene, and allow to analyze the content of an image, or to even compare two images semantically, i.e. with respect to their contents and the relations between their objects.
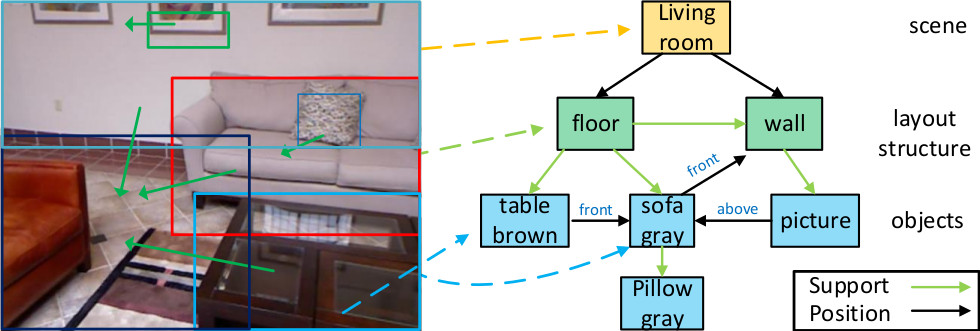
Figure 1: Example of an observed scene (left) and the scene graph constructed from it (right).
If you are looking for an interesting topic for you bachelor or master thesis, please contact Wentong Liao or Hanno Ackermann.
If you are looking for a topic for your Master or Bachelor thesis, and you are interested in analyzing and modelling abstract problems, please do not hesitate to contact Wentong Liao or Hanno Ackermann. You are required to have good programming skills (MatLab, Python, Java or C++) and you need a good understanding of, for instance, linear algebra or statistics.